
 Senior Researcher at ByteDance
Senior Researcher at ByteDance Master in Bupt
Master in BuptI am a Senior Researcher in the Intelligent Creation department at ByteDance, where I have been working since graduating with my Master's degree from Beijing University of Posts and Telecommunications (BUPT) in 2020.
My professional journey is deeply rooted in the fascinating field of Generative AI. During the era of Generative Adversarial Networks (GANs), I embarked on pioneering research in visual synthesis and manipulation. As the emergence of Diffusion models has driven the evolution of the technological landscape, I have consistently remained at the forefront of exploring controllable visual generation, striving to achieve unparalleled realism and precision. Currently, I am dedicated to tackling the core challenges in the dynamic domain of AI video generation — a pursuit I firmly believe is a crucial pathway toward the grand vision of Artificial General Intelligence (AGI).
Please feel free to reach out for collaborations, internships, or full-time opportunities.
Education
-
Beijing University of Posts and TelecommunicationsM.S. in Information and Communication EngineeringSep. 2017 - Jul. 2020
-
 Tiangong UniversityB.S. in Electronic InformationSep. 2013 - Jul. 2017
Tiangong UniversityB.S. in Electronic InformationSep. 2013 - Jul. 2017
Experience
-
ByteDanceMultimodal Generation ResearcherJun. 2020 - Present
-
 Horizon RoboticsResearch InternNov. 2019 - Mar. 2020
Horizon RoboticsResearch InternNov. 2019 - Mar. 2020 -
 SenseTimeResearch InternMar. 2019 - Aug. 2019
SenseTimeResearch InternMar. 2019 - Aug. 2019
News
Selected Publications (view all )

HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
Liyang Chen*, Tiangxiang Ma*, Jiawei Liu, Bingchuan Li, Zhuowei Chen, Lijie Liu, Xu He, Gen Li, Qian He, Zhiyong Wu
AAAI 2026
We introduce HuMo, a unified Human-Centric Video Generation framework that overcomes multimodal coordination challenges through a new high-quality dataset and a progressive training paradigm, achieving state-of-the-art subject preservation and audio-visual sync.
HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
Liyang Chen*, Tiangxiang Ma*, Jiawei Liu, Bingchuan Li, Zhuowei Chen, Lijie Liu, Xu He, Gen Li, Qian He, Zhiyong Wu
AAAI 2026
We introduce HuMo, a unified Human-Centric Video Generation framework that overcomes multimodal coordination challenges through a new high-quality dataset and a progressive training paradigm, achieving state-of-the-art subject preservation and audio-visual sync.
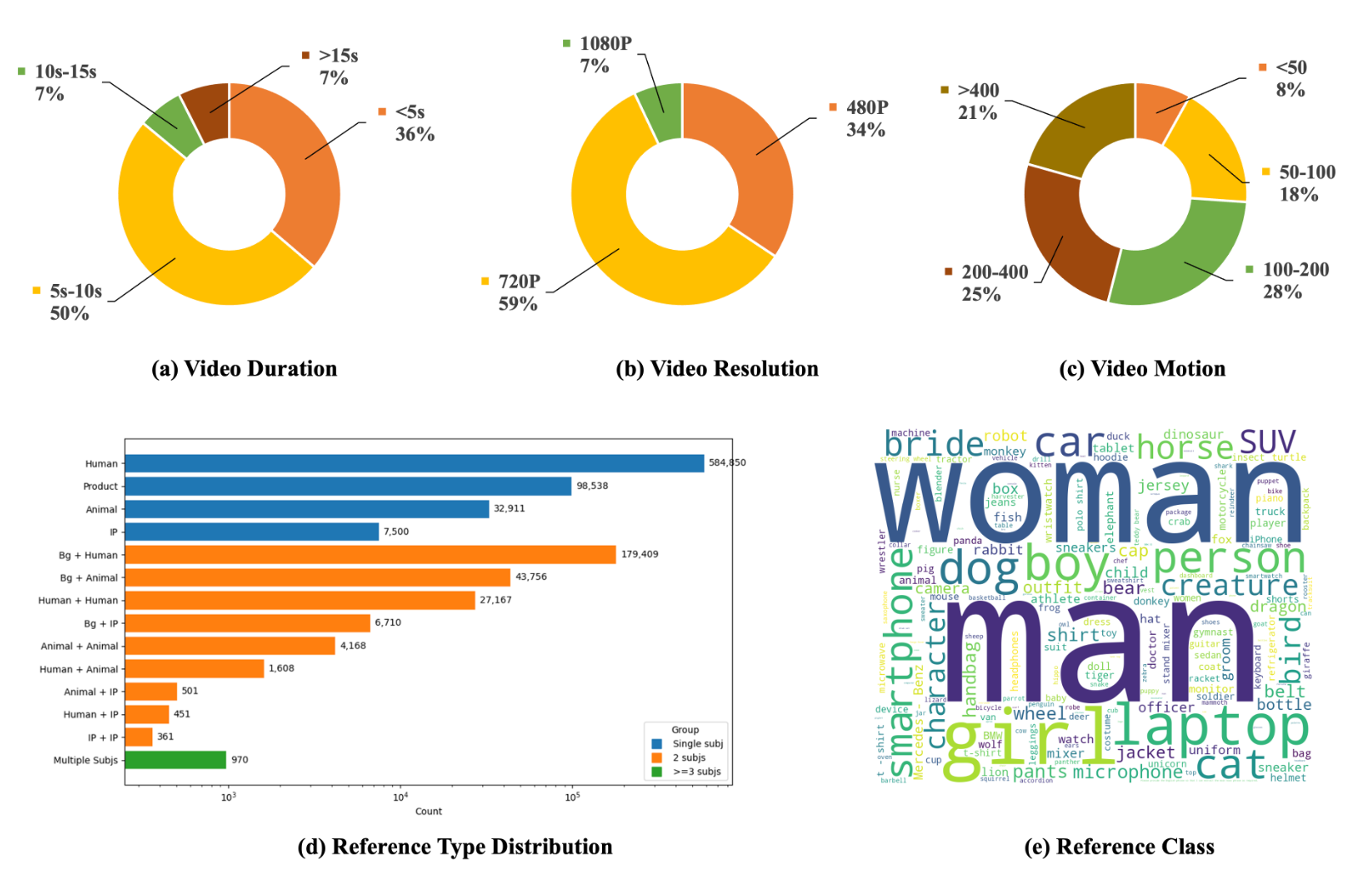
Phantom-Data: Towards a General Subject-Consistent Video Generation Dataset
Zhuowei Chen*, Bingchuan Li*, Tiangxiang Ma*, Lijie Liu*, Mingcong Liu, Yi Zhang, Gen Li, Xinghui Li, Siyu Zhou, Qian He, Xinglong Wu
Arxiv 2025
To address the subject-background entanglement in subject-to-video generation, we introduce Phantom-Data, the first general-purpose cross-pair consistency dataset, which significantly improves prompt alignment and visual quality while preserving identity.
Phantom-Data: Towards a General Subject-Consistent Video Generation Dataset
Zhuowei Chen*, Bingchuan Li*, Tiangxiang Ma*, Lijie Liu*, Mingcong Liu, Yi Zhang, Gen Li, Xinghui Li, Siyu Zhou, Qian He, Xinglong Wu
Arxiv 2025
To address the subject-background entanglement in subject-to-video generation, we introduce Phantom-Data, the first general-purpose cross-pair consistency dataset, which significantly improves prompt alignment and visual quality while preserving identity.
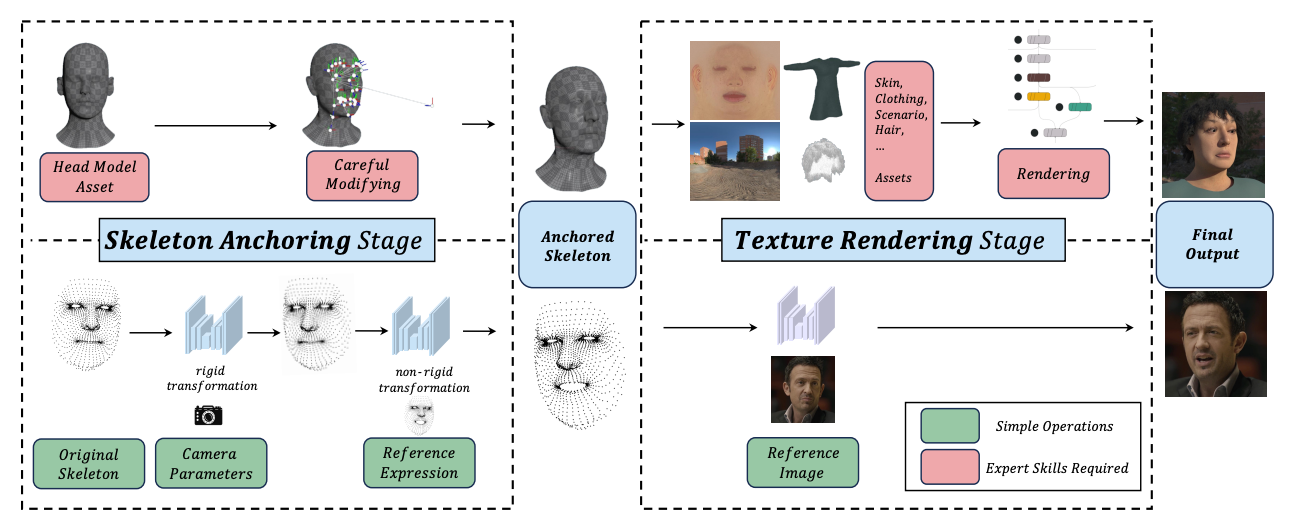
OneGT: One-Shot Geometry-Texture Neural Rendering for Head Avatars
Jinshu Chen, Bingchuan Li, Feiwei Zhang, Songtao Zhao, Qian He
ICCV 2025
We present OneGT that adheres to the frameworks of the rendering tools, while restructuring individual stages of the rendering pipeline through neural networks
OneGT: One-Shot Geometry-Texture Neural Rendering for Head Avatars
Jinshu Chen, Bingchuan Li, Feiwei Zhang, Songtao Zhao, Qian He
ICCV 2025
We present OneGT that adheres to the frameworks of the rendering tools, while restructuring individual stages of the rendering pipeline through neural networks

Phantom: Subject-Consistent Video Generation via Cross-Modal Alignment
Lijie Liu*, Tiangxiang Ma*, Bingchuan Li*, Zhuowei Chen*, Jiawei Liu, Gen Li, Siyu Zhou, Qian He, Xinglong Wu
ICCV 2025 Spotlight
A unified framework that learns cross-modal alignment from text-image-video triplets to achieve high-fidelity, subject-consistent videos while resolving content leakage and multi-subject confusion.
Phantom: Subject-Consistent Video Generation via Cross-Modal Alignment
Lijie Liu*, Tiangxiang Ma*, Bingchuan Li*, Zhuowei Chen*, Jiawei Liu, Gen Li, Siyu Zhou, Qian He, Xinglong Wu
ICCV 2025 Spotlight
A unified framework that learns cross-modal alignment from text-image-video triplets to achieve high-fidelity, subject-consistent videos while resolving content leakage and multi-subject confusion.
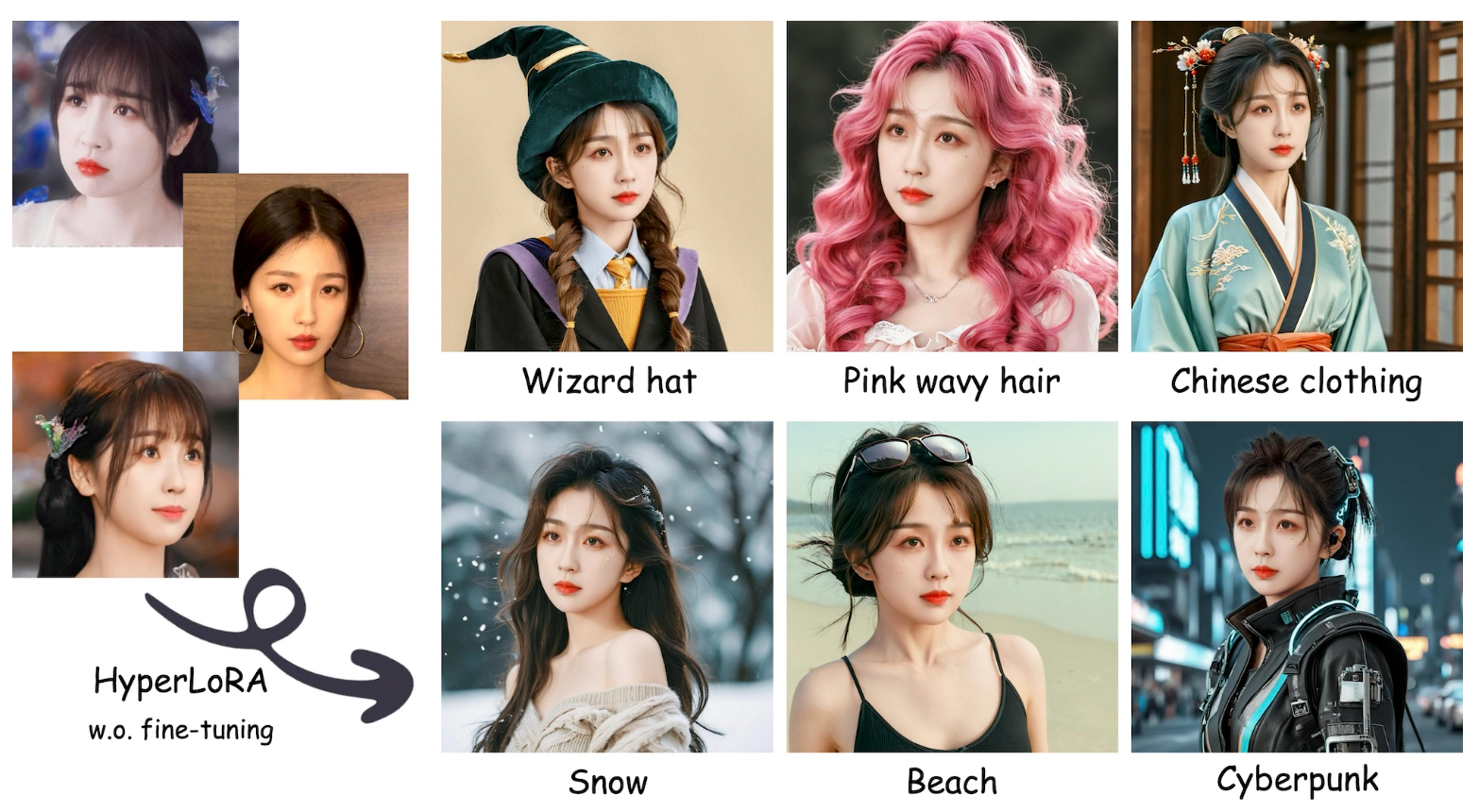
HyperLoRA: Parameter-Efficient Adaptive Generation for Portrait Synthesis
Mengtian Li, Jinshu Chen, Wanquan Feng, Bingchuan Li, Fei Dai, Songtao Zhao, Qian He
CVPR 2025 Spotlight
We introduce HyperLoRA, a parameter-efficient method that generates adaptive LoRA weights to achieve high-fidelity, zero-shot personalized portrait synthesis, merging the high performance of LoRA with the zero-shot capability of adapter-based techniques.
HyperLoRA: Parameter-Efficient Adaptive Generation for Portrait Synthesis
Mengtian Li, Jinshu Chen, Wanquan Feng, Bingchuan Li, Fei Dai, Songtao Zhao, Qian He
CVPR 2025 Spotlight
We introduce HyperLoRA, a parameter-efficient method that generates adaptive LoRA weights to achieve high-fidelity, zero-shot personalized portrait synthesis, merging the high performance of LoRA with the zero-shot capability of adapter-based techniques.
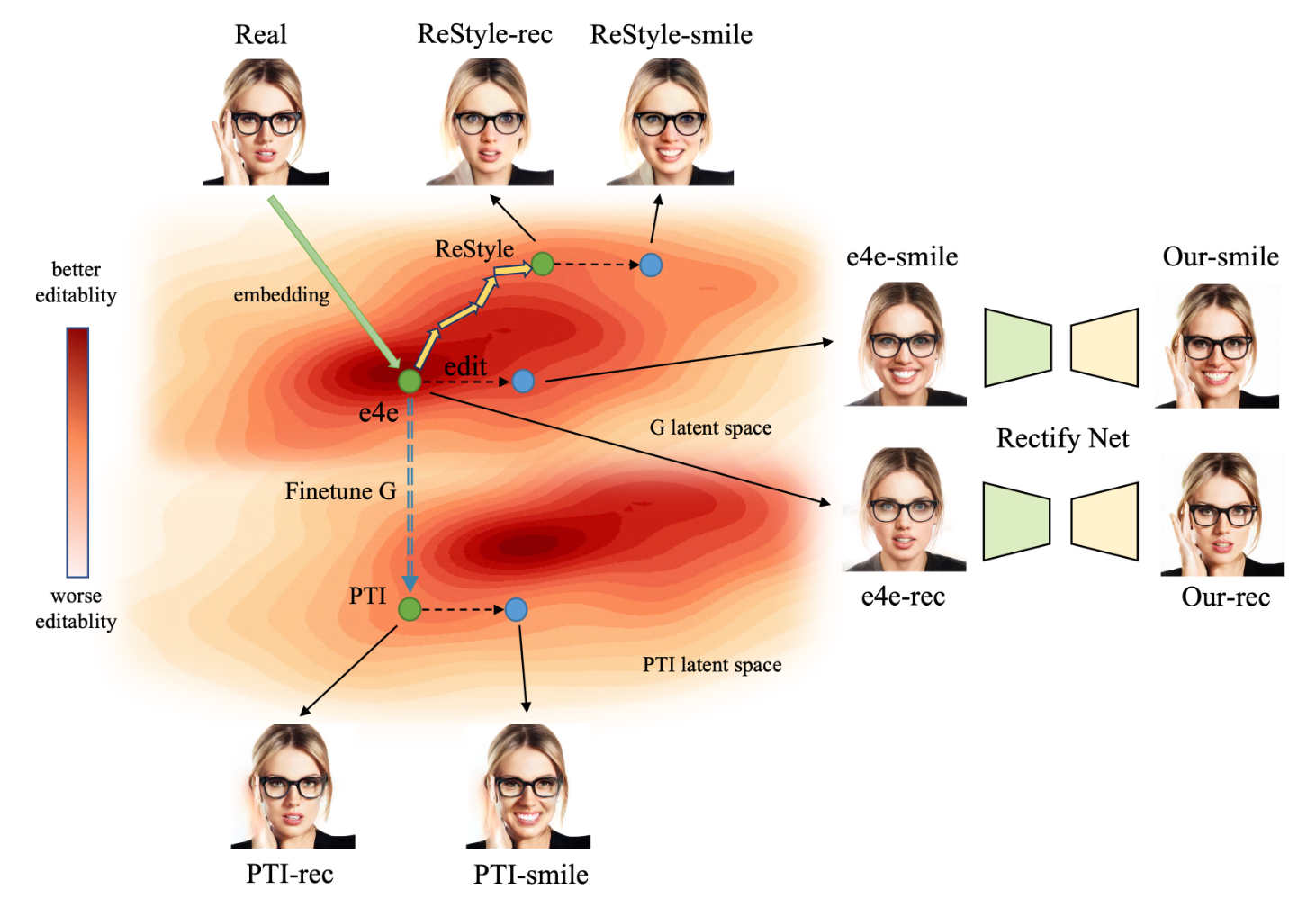
ReGANIE: Rectifying GAN Inversion Errors for Accurate Real Image Editing
Bingchuan Li, Tiangxiang Ma, Peng Zhang, Miao Hua, Wei Liu, Qian He, Zili Yi
AAAI 2023 Oral
To overcome the reconstruction-editability trade-off in StyleGAN inversion, we propose a two-phase framework that first uses an inversion network for editing and then a rectifying network to correct errors, enabling accurate real image manipulation with near-perfect reconstruction.
ReGANIE: Rectifying GAN Inversion Errors for Accurate Real Image Editing
Bingchuan Li, Tiangxiang Ma, Peng Zhang, Miao Hua, Wei Liu, Qian He, Zili Yi
AAAI 2023 Oral
To overcome the reconstruction-editability trade-off in StyleGAN inversion, we propose a two-phase framework that first uses an inversion network for editing and then a rectifying network to correct errors, enabling accurate real image manipulation with near-perfect reconstruction.
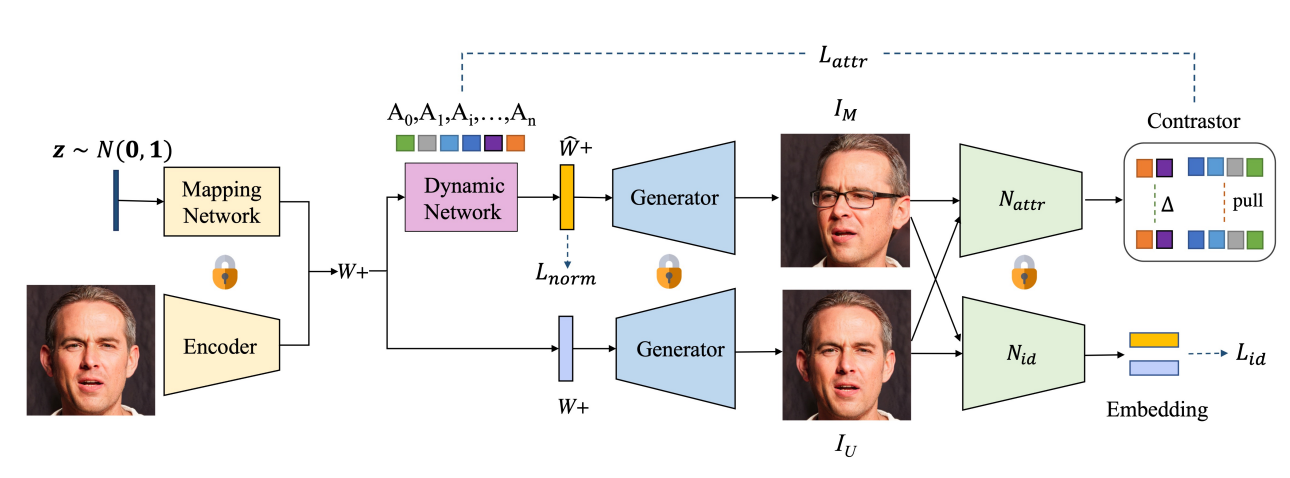
Dystyle: Dynamic neural network for multi-attribute-conditioned style editing
Bingchuan Li*, Shaofei Cai*, Wei Liu, Peng Zhang, Miao Hua, Qian He, Zili Yi
WACV 2023
We design a Dynamic Style Manipulation Network (DyStyle) whose structure and parameters vary by input samples, to perform nonlinear and adaptive manipulation of latent codes for flexible and precise attribute control
Dystyle: Dynamic neural network for multi-attribute-conditioned style editing
Bingchuan Li*, Shaofei Cai*, Wei Liu, Peng Zhang, Miao Hua, Qian He, Zili Yi
WACV 2023
We design a Dynamic Style Manipulation Network (DyStyle) whose structure and parameters vary by input samples, to perform nonlinear and adaptive manipulation of latent codes for flexible and precise attribute control