2025

HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
Liyang Chen*, Tiangxiang Ma*, Jiawei Liu, Bingchuan Li, Zhuowei Chen, Lijie Liu, Xu He, Gen Li, Qian He, Zhiyong Wu
AAAI 2026
We introduce HuMo, a unified Human-Centric Video Generation framework that overcomes multimodal coordination challenges through a new high-quality dataset and a progressive training paradigm, achieving state-of-the-art subject preservation and audio-visual sync.
HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
Liyang Chen*, Tiangxiang Ma*, Jiawei Liu, Bingchuan Li, Zhuowei Chen, Lijie Liu, Xu He, Gen Li, Qian He, Zhiyong Wu
AAAI 2026
We introduce HuMo, a unified Human-Centric Video Generation framework that overcomes multimodal coordination challenges through a new high-quality dataset and a progressive training paradigm, achieving state-of-the-art subject preservation and audio-visual sync.

OmniInsert: Mask-Free Video Insertion of Any Reference via Diffusion Transformer Models
Jinshu Chen*, Xinghui Li*, Xu bai*, Tianxiang Ma, Pengze Zhang, Zhuowei Chen, Gen Li, Lijie Liu, Songtao Zhao, Bingchuan Li, Qian He
Arxiv 2025
OmniInsert introduces a mask-free video insertion method using Diffusion Transformer Models, enabling the seamless integration of any reference object into a video without the need for manual mask annotation.
OmniInsert: Mask-Free Video Insertion of Any Reference via Diffusion Transformer Models
Jinshu Chen*, Xinghui Li*, Xu bai*, Tianxiang Ma, Pengze Zhang, Zhuowei Chen, Gen Li, Lijie Liu, Songtao Zhao, Bingchuan Li, Qian He
Arxiv 2025
OmniInsert introduces a mask-free video insertion method using Diffusion Transformer Models, enabling the seamless integration of any reference object into a video without the need for manual mask annotation.
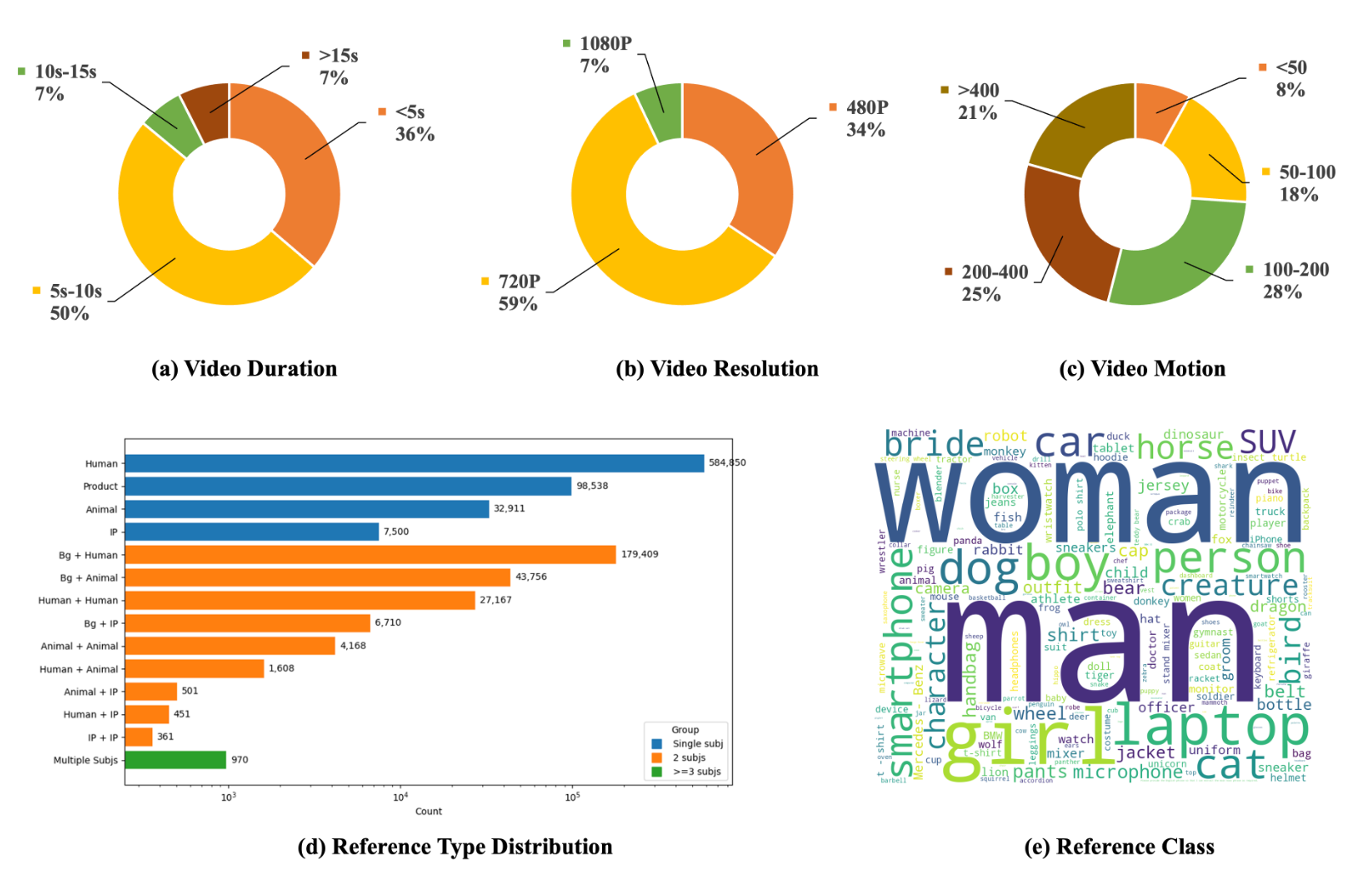
Phantom-Data: Towards a General Subject-Consistent Video Generation Dataset
Zhuowei Chen*, Bingchuan Li*, Tiangxiang Ma*, Lijie Liu*, Mingcong Liu, Yi Zhang, Gen Li, Xinghui Li, Siyu Zhou, Qian He, Xinglong Wu
ICLR 2026
To address the subject-background entanglement in subject-to-video generation, we introduce Phantom-Data, the first general-purpose cross-pair consistency dataset, which significantly improves prompt alignment and visual quality while preserving identity.
Phantom-Data: Towards a General Subject-Consistent Video Generation Dataset
Zhuowei Chen*, Bingchuan Li*, Tiangxiang Ma*, Lijie Liu*, Mingcong Liu, Yi Zhang, Gen Li, Xinghui Li, Siyu Zhou, Qian He, Xinglong Wu
ICLR 2026
To address the subject-background entanglement in subject-to-video generation, we introduce Phantom-Data, the first general-purpose cross-pair consistency dataset, which significantly improves prompt alignment and visual quality while preserving identity.
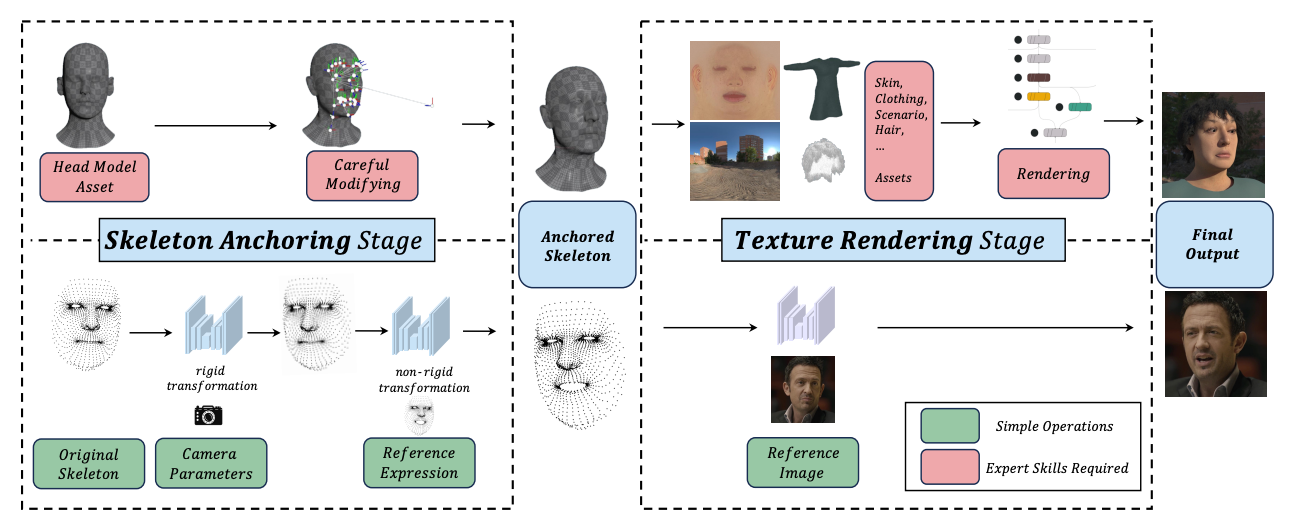
OneGT: One-Shot Geometry-Texture Neural Rendering for Head Avatars
Jinshu Chen, Bingchuan Li, Feiwei Zhang, Songtao Zhao, Qian He
ICCV 2025
We present OneGT that adheres to the frameworks of the rendering tools, while restructuring individual stages of the rendering pipeline through neural networks
OneGT: One-Shot Geometry-Texture Neural Rendering for Head Avatars
Jinshu Chen, Bingchuan Li, Feiwei Zhang, Songtao Zhao, Qian He
ICCV 2025
We present OneGT that adheres to the frameworks of the rendering tools, while restructuring individual stages of the rendering pipeline through neural networks

Phantom: Subject-Consistent Video Generation via Cross-Modal Alignment
Lijie Liu*, Tiangxiang Ma*, Bingchuan Li*, Zhuowei Chen*, Jiawei Liu, Gen Li, Siyu Zhou, Qian He, Xinglong Wu
ICCV 2025 Spotlight
A unified framework that learns cross-modal alignment from text-image-video triplets to achieve high-fidelity, subject-consistent videos while resolving content leakage and multi-subject confusion.
Phantom: Subject-Consistent Video Generation via Cross-Modal Alignment
Lijie Liu*, Tiangxiang Ma*, Bingchuan Li*, Zhuowei Chen*, Jiawei Liu, Gen Li, Siyu Zhou, Qian He, Xinglong Wu
ICCV 2025 Spotlight
A unified framework that learns cross-modal alignment from text-image-video triplets to achieve high-fidelity, subject-consistent videos while resolving content leakage and multi-subject confusion.

Seaweed-7b: Cost-effective training of video generation foundation model
T Seawead
Arxiv 2025
Seaweed-7B is a 7-billion-parameter video generation model trained from scratch in just 665k H100 hours, delivering competitive or superior results to much larger rivals. Its strong generalization allows cheap downstream adaptation via light fine-tuning or continued training.
Seaweed-7b: Cost-effective training of video generation foundation model
T Seawead
Arxiv 2025
Seaweed-7B is a 7-billion-parameter video generation model trained from scratch in just 665k H100 hours, delivering competitive or superior results to much larger rivals. Its strong generalization allows cheap downstream adaptation via light fine-tuning or continued training.
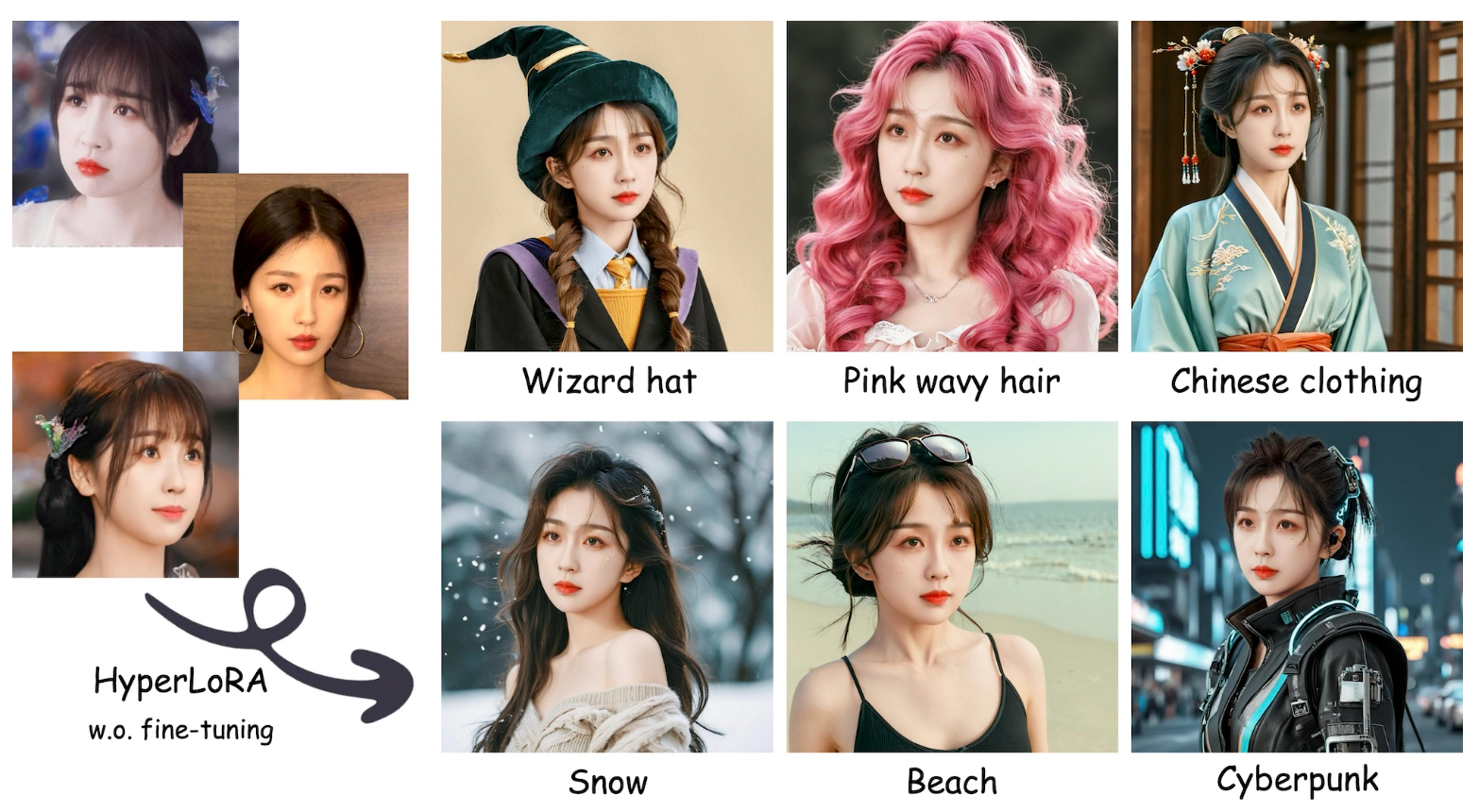
HyperLoRA: Parameter-Efficient Adaptive Generation for Portrait Synthesis
Mengtian Li, Jinshu Chen, Wanquan Feng, Bingchuan Li, Fei Dai, Songtao Zhao, Qian He
CVPR 2025 Spotlight
We introduce HyperLoRA, a parameter-efficient method that generates adaptive LoRA weights to achieve high-fidelity, zero-shot personalized portrait synthesis, merging the high performance of LoRA with the zero-shot capability of adapter-based techniques.
HyperLoRA: Parameter-Efficient Adaptive Generation for Portrait Synthesis
Mengtian Li, Jinshu Chen, Wanquan Feng, Bingchuan Li, Fei Dai, Songtao Zhao, Qian He
CVPR 2025 Spotlight
We introduce HyperLoRA, a parameter-efficient method that generates adaptive LoRA weights to achieve high-fidelity, zero-shot personalized portrait synthesis, merging the high performance of LoRA with the zero-shot capability of adapter-based techniques.
2024
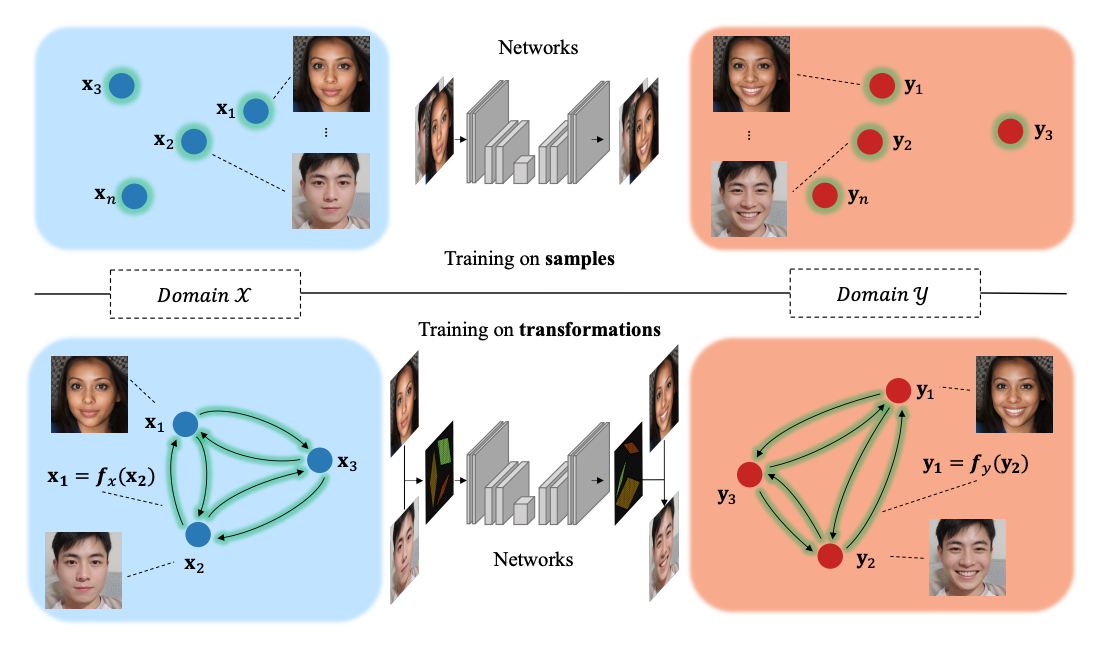
Customize Your Own Paired Data via Few-shot Way
Jinshu Chen, Bingchuan Li, Miao Hua, Pengkai Xu, Qian He
CVPRW 2024
The task we focus on is how to enable the users to customize their desired effects through only few image pairs. In our proposed framework, a novel few-shot learning mechanism based on the directional transformations among samples is introduced and expands the learnable space exponentially.
Customize Your Own Paired Data via Few-shot Way
Jinshu Chen, Bingchuan Li, Miao Hua, Pengkai Xu, Qian He
CVPRW 2024
The task we focus on is how to enable the users to customize their desired effects through only few image pairs. In our proposed framework, a novel few-shot learning mechanism based on the directional transformations among samples is introduced and expands the learnable space exponentially.
2023
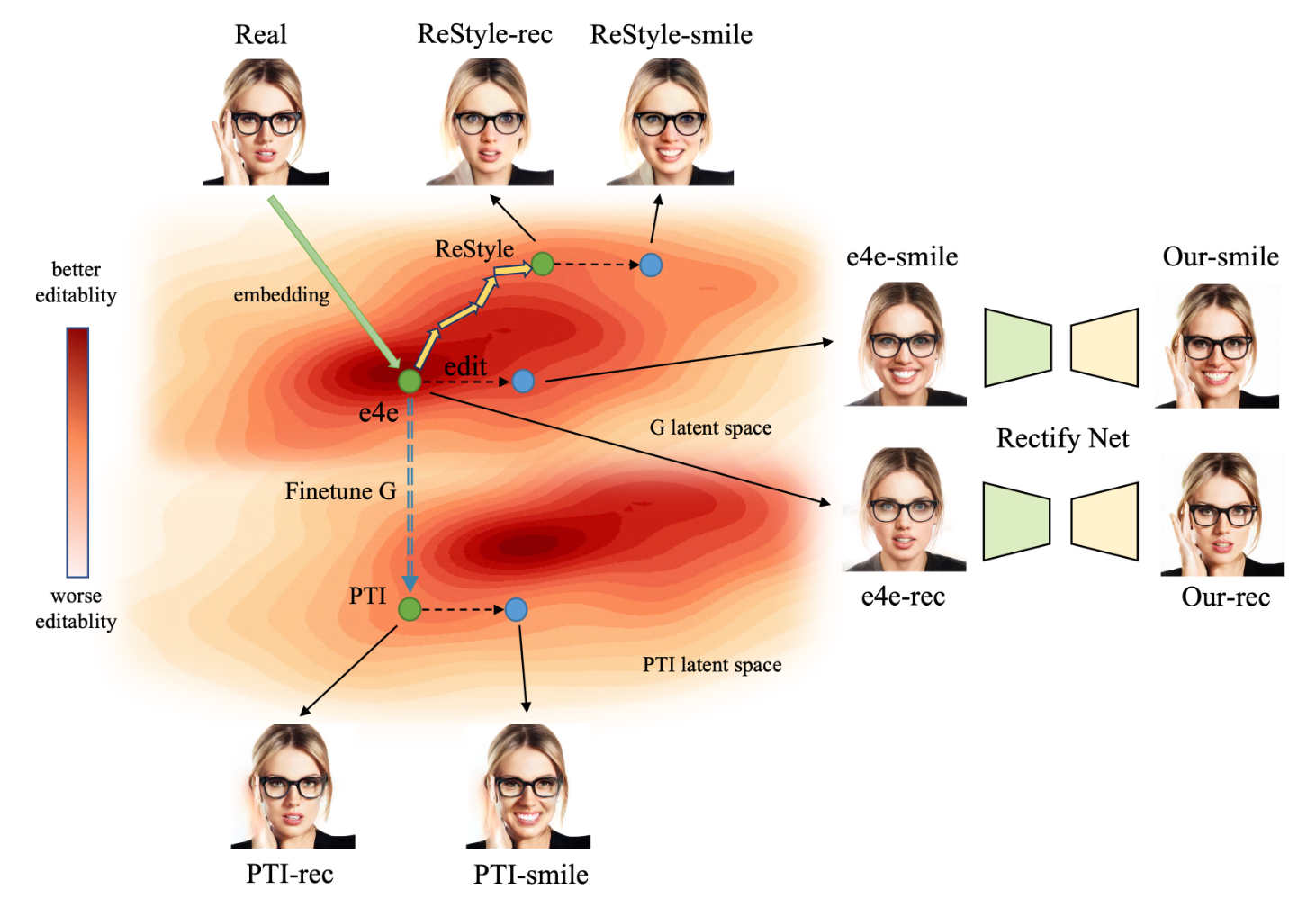
ReGANIE: Rectifying GAN Inversion Errors for Accurate Real Image Editing
Bingchuan Li, Tiangxiang Ma, Peng Zhang, Miao Hua, Wei Liu, Qian He, Zili Yi
AAAI 2023 Oral
To overcome the reconstruction-editability trade-off in StyleGAN inversion, we propose a two-phase framework that first uses an inversion network for editing and then a rectifying network to correct errors, enabling accurate real image manipulation with near-perfect reconstruction.
ReGANIE: Rectifying GAN Inversion Errors for Accurate Real Image Editing
Bingchuan Li, Tiangxiang Ma, Peng Zhang, Miao Hua, Wei Liu, Qian He, Zili Yi
AAAI 2023 Oral
To overcome the reconstruction-editability trade-off in StyleGAN inversion, we propose a two-phase framework that first uses an inversion network for editing and then a rectifying network to correct errors, enabling accurate real image manipulation with near-perfect reconstruction.
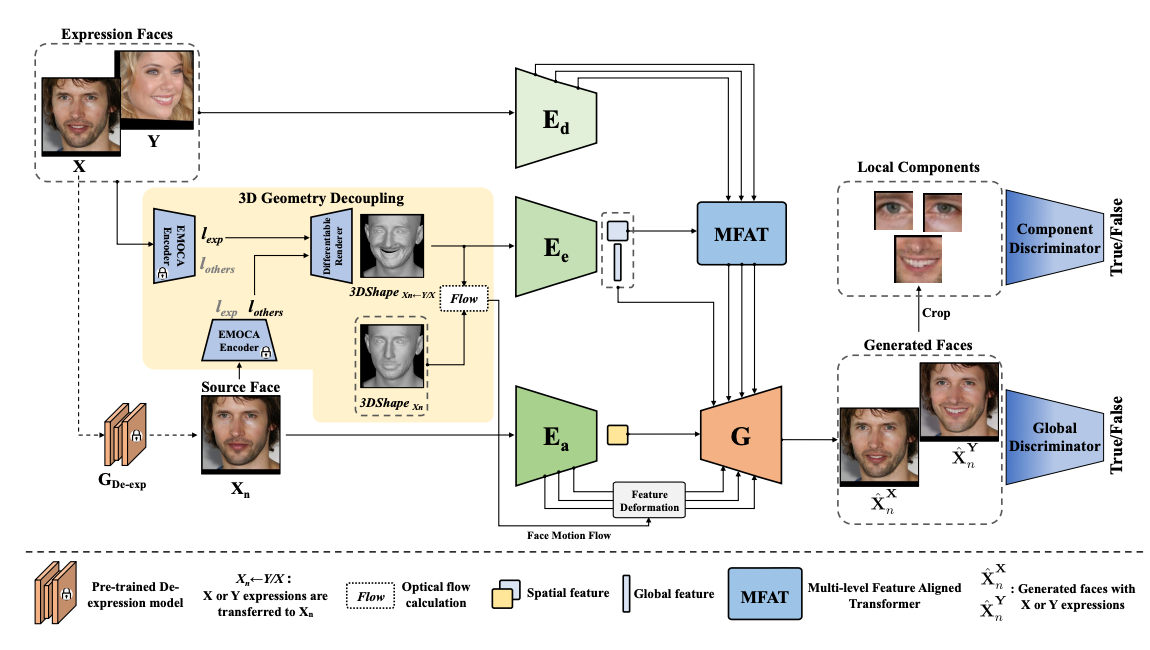
GaFET: learning geometry-aware facial expression translation from in-the-wild images
Tiangxiang Ma*, Bingchuan Li*, Qian He, Jingdong Dong, Tieniu Tan
ICCV 2023
We introduce a novel Geometry-aware Facial Expression Translation (GaFET) framework, which is based on parametric 3D facial representations and can stably decoupled expression
GaFET: learning geometry-aware facial expression translation from in-the-wild images
Tiangxiang Ma*, Bingchuan Li*, Qian He, Jingdong Dong, Tieniu Tan
ICCV 2023
We introduce a novel Geometry-aware Facial Expression Translation (GaFET) framework, which is based on parametric 3D facial representations and can stably decoupled expression
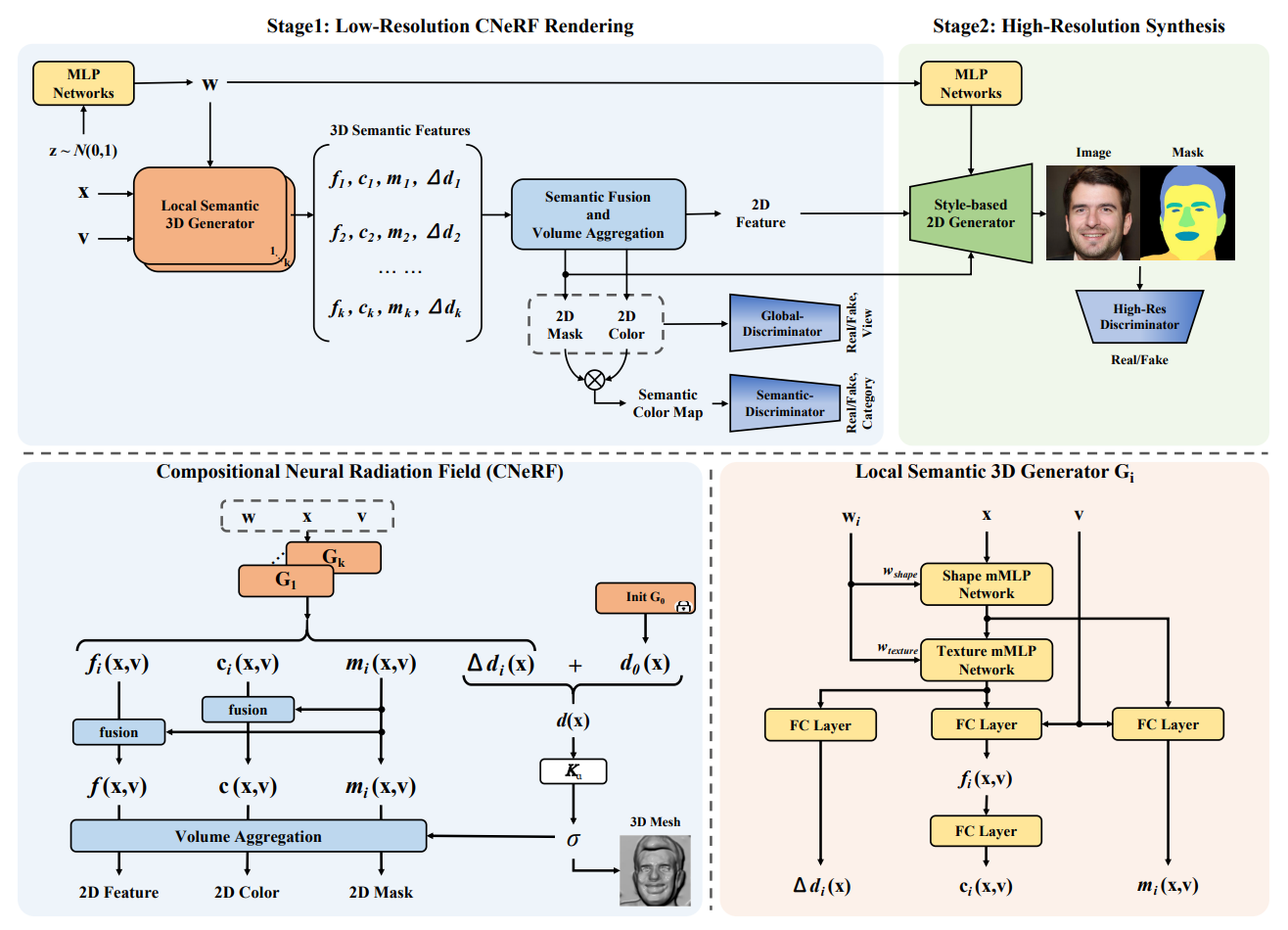
Semantic 3D-aware Portrait Synthesis and Manipulation Based on Compositional Neural Radiance Field
Tiangxiang Ma*, Bingchuan Li*, Qian He, Jingdong Dong, Tieniu Tan
AAAI 2023 Oral
Since NeRF renders an image pixel by pixel, it is possible to split NeRF in the spatial dimension. We propose a Compositional Neural Radiance Field (CNeRF) for semantic 3D-aware portrait synthesis and manipulation. CNeRF divides the image by semantic regions and learns an independent neural radiance field for each region, and finally fuses them and renders the complete image
Semantic 3D-aware Portrait Synthesis and Manipulation Based on Compositional Neural Radiance Field
Tiangxiang Ma*, Bingchuan Li*, Qian He, Jingdong Dong, Tieniu Tan
AAAI 2023 Oral
Since NeRF renders an image pixel by pixel, it is possible to split NeRF in the spatial dimension. We propose a Compositional Neural Radiance Field (CNeRF) for semantic 3D-aware portrait synthesis and manipulation. CNeRF divides the image by semantic regions and learns an independent neural radiance field for each region, and finally fuses them and renders the complete image
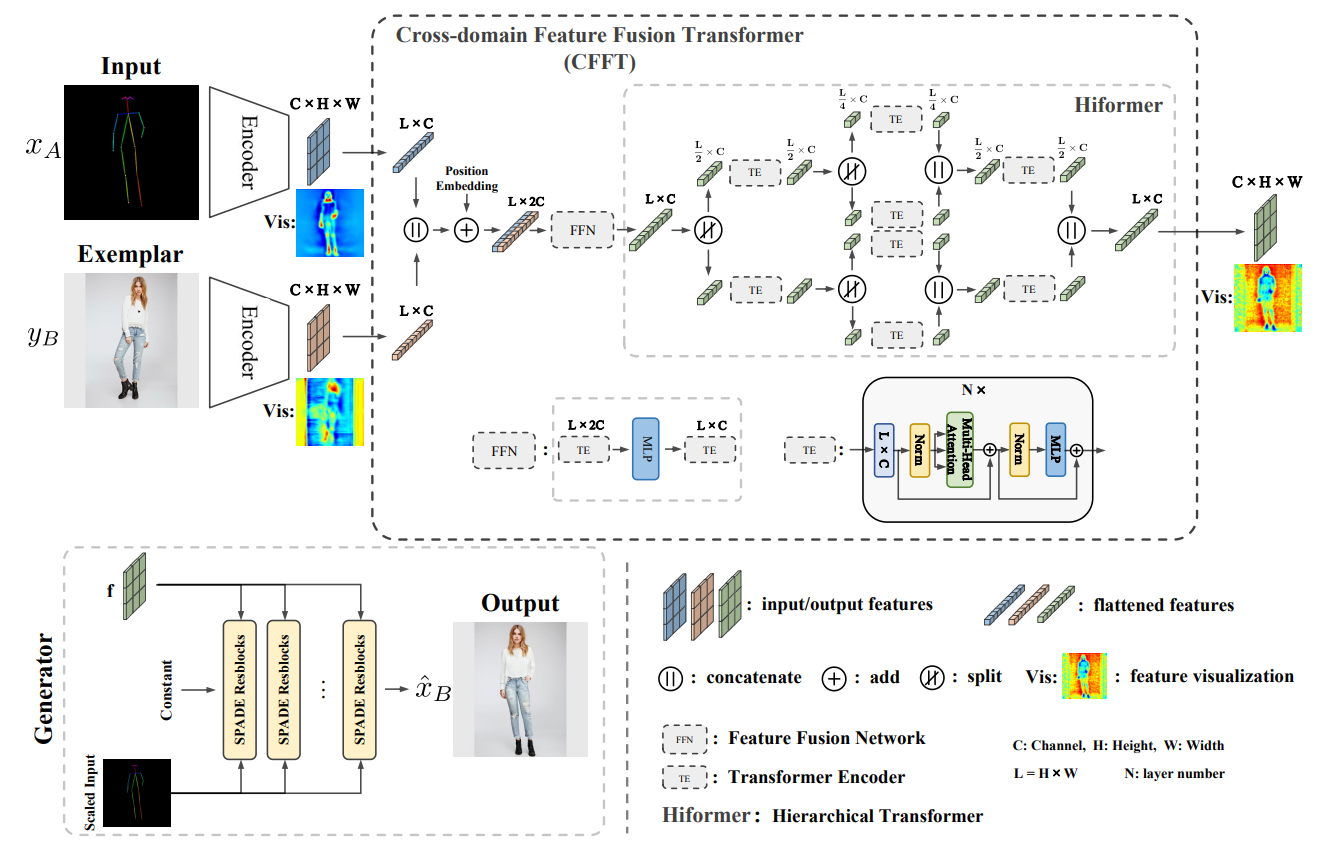
CFFT-GAN: cross-domain feature fusion transformer for exemplar-based image translation
Tiangxiang Ma, Bingchuan Li, Wei Liu, Miao Hua, Jingdong Dong, Tieniu Tan
AAAI 2023 Oral
We propose a more general learning approach by considering two domain features as a whole and learning both inter-domain correspondence and intra-domain potential information interactions. Specifically, we design a Cross-domain Feature Fusion Transformer (CFFT) to learn inter- and intra-domain feature fusion.
CFFT-GAN: cross-domain feature fusion transformer for exemplar-based image translation
Tiangxiang Ma, Bingchuan Li, Wei Liu, Miao Hua, Jingdong Dong, Tieniu Tan
AAAI 2023 Oral
We propose a more general learning approach by considering two domain features as a whole and learning both inter-domain correspondence and intra-domain potential information interactions. Specifically, we design a Cross-domain Feature Fusion Transformer (CFFT) to learn inter- and intra-domain feature fusion.
2022
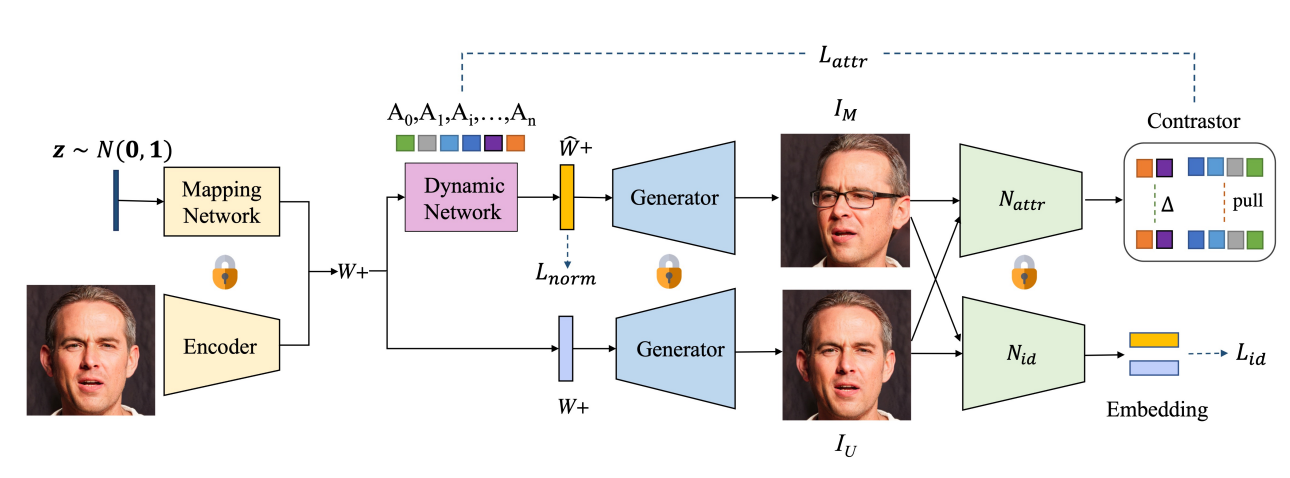
Dystyle: Dynamic neural network for multi-attribute-conditioned style editing
Bingchuan Li*, Shaofei Cai*, Wei Liu, Peng Zhang, Miao Hua, Qian He, Zili Yi
WACV 2023
We design a Dynamic Style Manipulation Network (DyStyle) whose structure and parameters vary by input samples, to perform nonlinear and adaptive manipulation of latent codes for flexible and precise attribute control
Dystyle: Dynamic neural network for multi-attribute-conditioned style editing
Bingchuan Li*, Shaofei Cai*, Wei Liu, Peng Zhang, Miao Hua, Qian He, Zili Yi
WACV 2023
We design a Dynamic Style Manipulation Network (DyStyle) whose structure and parameters vary by input samples, to perform nonlinear and adaptive manipulation of latent codes for flexible and precise attribute control
2021
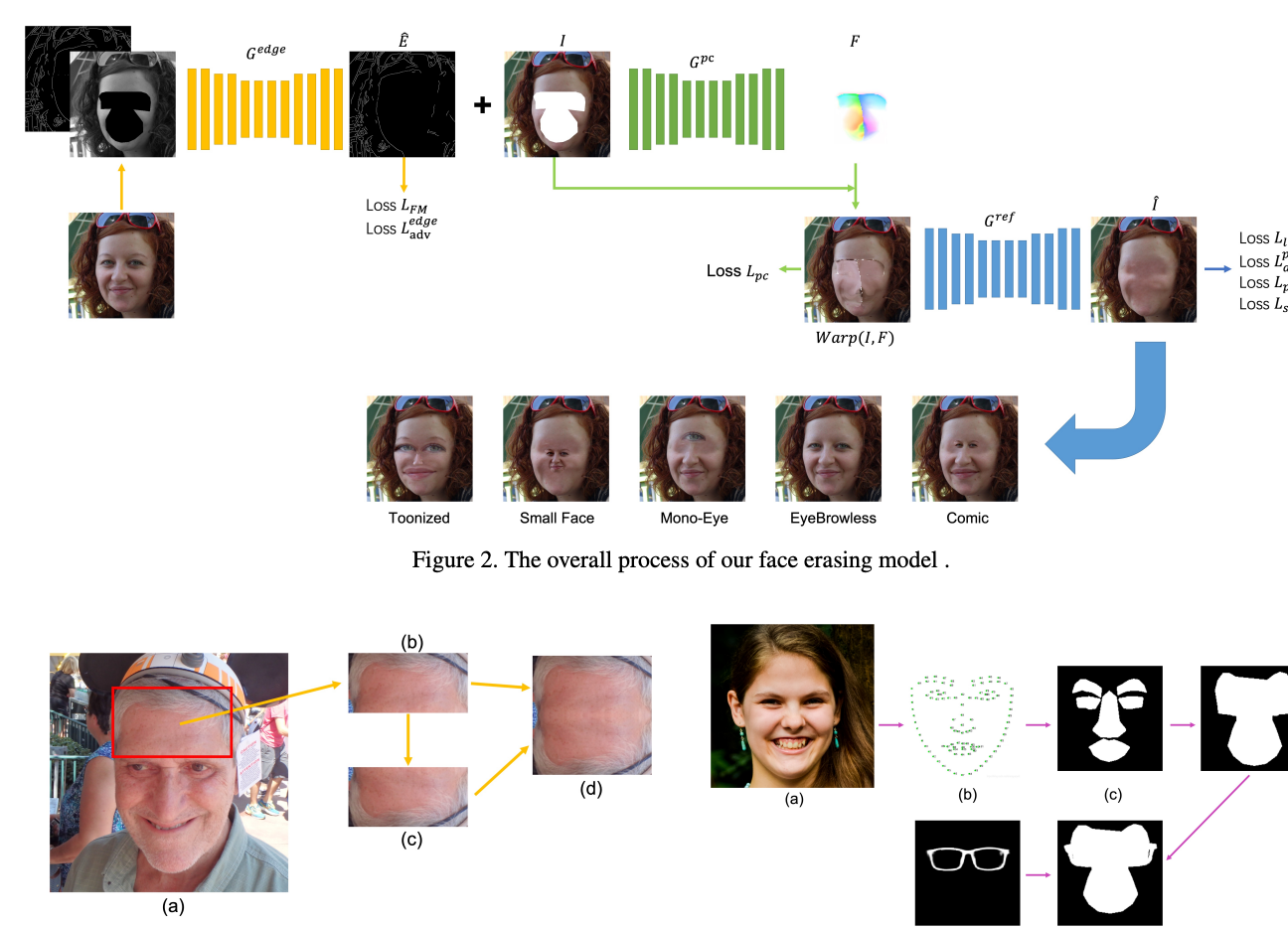
FaceEraser: Removing Facial Parts for Augmented Reality
Miao Hua, Lijie Liu, Zhengcheng Liu, Qian He, Bingchuan Li, Zili Yi
ICCVW 2021
To enable facial augmented reality, we introduce FaceEraser, which uses a novel data generation technique and network architecture to inpaint facial parts, overcoming the lack of real 'blank face' training data.
FaceEraser: Removing Facial Parts for Augmented Reality
Miao Hua, Lijie Liu, Zhengcheng Liu, Qian He, Bingchuan Li, Zili Yi
ICCVW 2021
To enable facial augmented reality, we introduce FaceEraser, which uses a novel data generation technique and network architecture to inpaint facial parts, overcoming the lack of real 'blank face' training data.